ProblemStatement
Given a set of Indian names create new names using character-level recurrent neural network.
Step 01 - Processing the data
-
In this step we shall read the input words - Indian names as each sentence with ‘\n’ char at the end of each name we also create our vocabulary characters list
-
We need to maintain two hashtable char_to-index and index_to_char each of these are mappings of characters in vocabulary to an index and viceversa
Step 02 - Building the model
Building the model include the following:
a) Training the model
b) Optimizing:
b.1) Forward Prop
b.2) Backward Prop
b.3) Gradient Clipping
b.4) Parameters updation
c) Performing sampling -> to ensure the training.
2.1 - Gradient Clipping
Gradient clipping is performed to avoid the exploding gradients problem, in which the gradients suffer from having extremely high values.
Hence, given a range [-n, n] check if the value is within the range if:
a) num > n => num = n
b) num < -n => num = -n
2.2 - Sampling
Sampling the model is assuming that the model is trained and is ready to generate the next character and there by Indian name
when it is fed by an input character. Problem here would be only one name will be generated for one character. Here are the
steps for sampling:
Step 01: Retrieve the parameters into respective variables, and initalize the x and a_prev
Step 02: Calculate the a and y.
Note: The vectors **x** and **a** are 2D not 1D.
Step 03: Sampling, the y which is a result of softmax probability vector. If the highest probability index is concerned
everytime there shall be a problem of having single name for a input character. For this case, we shall consider random function np.random.choice().
Step 04: Updating the x
2.3 - Optimizing the Model
In this step we perform F.W.D propogation, B.W.D propogation, gradient Clipping and update the parameters
a) Perform F.W.D prop -> rnn_fwd_prop() method defined in utils
b) Perform B.W.D prop -> rnn_bck_prop() method defined in utils
c) Perform gradient clipping defined in step 2.1
d) Update the parameters -> update_parameters() method defined in utils
2.4 - Training the Model
a) In this we step we shall initialize the parameters -> Wax (n_x, n_a), Waa (n_a, n_a), Wya (n_y, n_a), b (n_a, 1), by(n_y, 1).
b) Calculate the initial loss. This is to ensure that we give a smooth calculation at every step where loss is calculated.
c) Prepare a list of dinosaurs name by stripping the ‘\n’. And shuffle this list.
d) Initialize a_prev (n_a, 1) with zeros.
e) Run the optimization loop over given number of iterations.
e.1) Retrieve each example & create a list of the char's in each example & map these char's to index using char_to_index.
e.2) Initalize X to [None] + above create list of indices of the example.
e.3) Initalize Y to indices list of example + char_to_index('\n').
e.4) Optimize the values (F.W.D Prop -> B.W.D Prop -> Gradient_Clipping -> Update_Parameters)
e.5) Perform sampling for every 2000 iterations to check if the model is training properly.
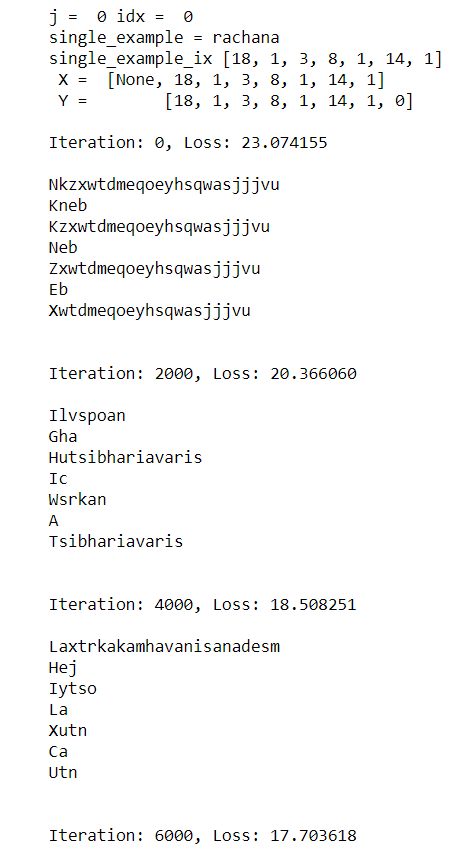
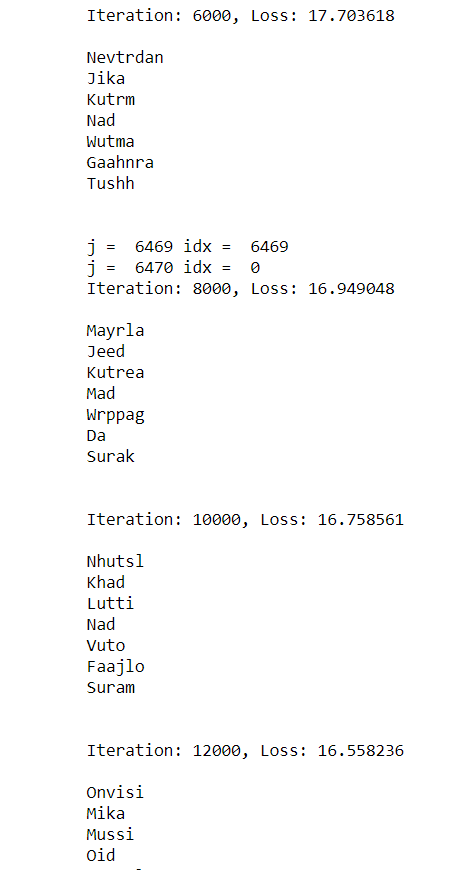
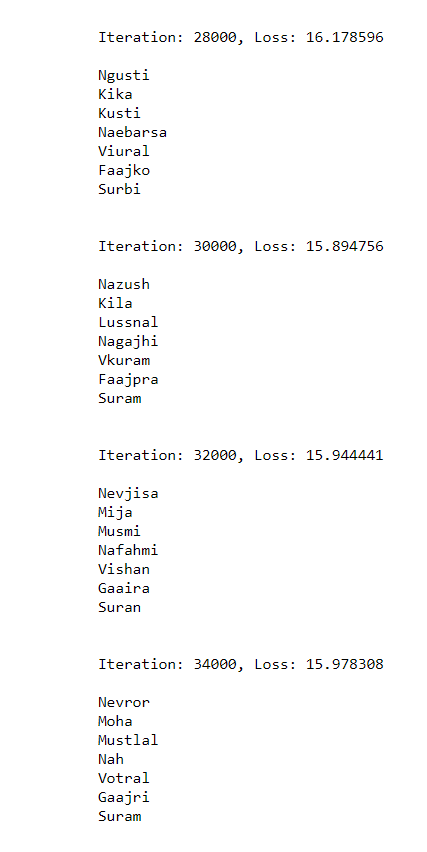
Code is available here. The output after iterations are below: